Key Considerations
To run LLM on SaladCloud, several key decisions need to be made first: Model: There are many LLM models available, open-source or proprietary, in various sizes, precisions and formats. The LLM inference typically requires a significant amount of VRAM, not just for the model parameters, but also for the KV-Cache during inference, which is heavily influenced by the batch size and context length. Models like 7B, 8B and 9B, as well as quantized 13B and 34B, can run smoothly on a GPU with 24GB of VRAM on SaladCloud, while larger models are not recommended. Inference Server: Several inference servers are available for running LLM models, including vLLM, TGI, Ollama, TensorRT-LLM, RayLLM, LMDeploy and llama.cpp. These servers differ in various aspects, including supported models, VRAM usage and efficiency, performance, throughput and additional features; and you should choose one that best meets your needs. Most of these servers provide container images that can be run directly on SaladCloud without modification. However, you can also create a custom wrapper image based on official images to add features like an I/O worker or model preloading. Alternatively, you can build your own inference server tailored to specific requirements. Service Access: If you need to provide real-time and on-demand chat services, deploying a container group with a container gateway is the easiest approach. However, if the requirement is to build a batch processing system where millions of prompts are processed without the need for immediate responses, a container group integrated with a job queue offers a more resilient and cost-effective solution.VRAM Usage
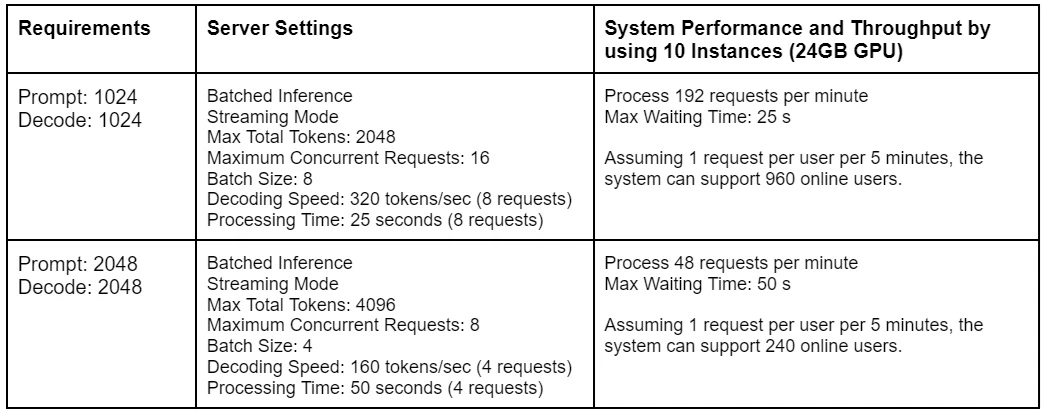
LLM inference consists of two stages: prefill and decode. In the prefill stage, the model processes the input prompt, computing their embeddings. In the decode stage, the model generates one token at a time conditioning on the prompt and all previously generated tokens. VRAM usage during LLM inference is primarily driven by the model parameters and the KV-Cache. The KV-Cache stores the key/value embeddings of the input prompt and all previously generated tokens. These embeddings are computed once and retained in memory for reuse during the decode stage of inference, which can significantly speed up the process. As the context length (encompassing both the input prompt and generated text) and batch size (the number of input prompts processed simultaneously) increase, the VRAM consumption of the KV-Cache can grow significantly. For example, with LLaMA 3.1 8B Instruct in 16-bit precision, the model parameters alone require approximately 16 GB of VRAM. The KV-Cache, for a batch size of 1 and a context length of 4096, uses about 2 GB of VRAM. Therefore, a GPU with 24 GB of VRAM can handle batched inference with around:- A batch size of 16 and a context length of 1024
- A batch size of 8 and a context length of 2048
- A batch size of 4 and a context length of 4096
- A batch size of 1 and a context length of 16384
Performance and Throughput
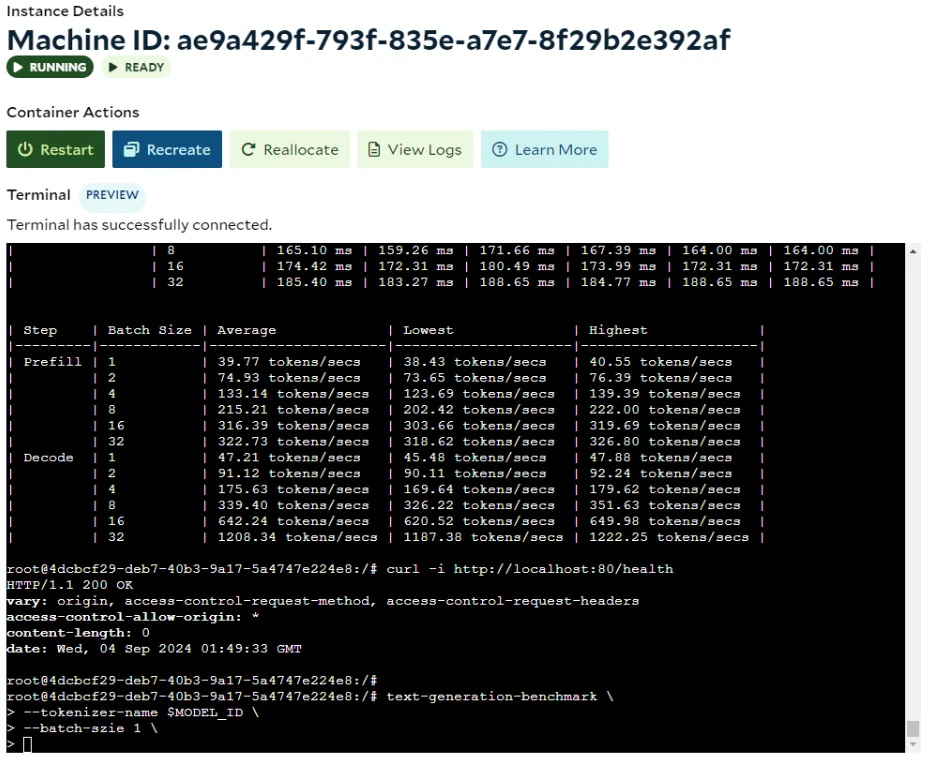
There are two key performance indicators for measuring the performance of LLM inference on a node: Time to First Token (TTFT): the speed of prefill, as nothing can be generated before the embeddings of input prompt is computed. This determines the waiting time for users to see the first generated token. Time Per Output Token (TPOT): the decoding speed, the number of generated tokens per unit time after prefill. This affects the overall processing time to provide the entire generated text. Typically, the prefill stage is brief because the prompt is processed in parallel. However, the decode stage takes much longer since tokens are generated one at a time. For the same context length, the longer the generated text, the greater the total processing time. Here is the test data for Llama 3.1 8B Instruct using Hugging Face’s TGI, from a PC equipped with an RTX 3090 running Windows WSL:- Processing Time = TPOT x Number of Generated Tokens
- Throughput = 1 / TPOT
- Total Time = TTFT + Processing Time
Longer context lengths not only increase waiting time and negatively impact user experience, but may also lead to the
server response timeout errors at the load balancer in front of the inference servers, which has a maximum timeout limit
of 100 seconds. Enabling token streaming on the servers allows tokens to be returned one by one, rather than waiting for
the entire response to be generated. This feature shows the generation progress in real-time, significantly enhancing
the user experience, and helping to avoid the timeout errors.
When more VRAM is available, batched inference can significantly increase throughput by effectively leveraging GPU cache
and parallel processing, while only slightly increasing the processing time. Here is the test data from the same PC:
Compared to batched inference, concurrent inference using multiprocessing or multithreading on a single GPU might limit
optimal GPU cache utilization and significantly impact performance, and is generally not recommended. This occurs
because each inference process operates independently, reducing the efficiency of GPU resource usage. Additionally,
multiprocessing consumes more VRAM, as each process requires its own CUDA context and loads a separate instance of the
model into GPU VRAM for inference.
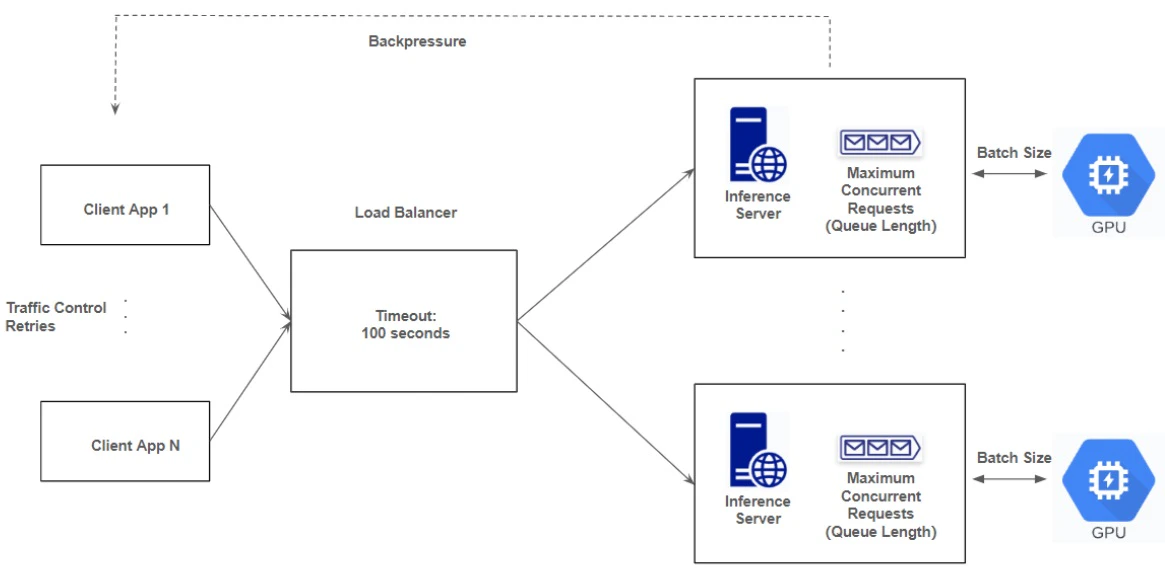
Many inference servers have a local queue to buffer requests and also support the continuous or dynamic batching. This
means that, upon completing a request within a batch, the server can automatically add a new request from the queue to
the batch and continue the inference process. These configurations can be managed using parameters such as
MAX_CONCURRENT_REQUESTS (the number of requests handled simultaneously, or the queue length) and MAX_BATCH_SIZE
(the number of requests grouped together for a batched inference).
These parameters must be carefully planned, tested and configured to increase throughput, enhance user experiences and
avoid system errors. Typically, MAX_CONCURRENT_REQUESTS should be larger than MAX_BATCH_SIZE to effectively buffer the
burst traffic, but if set too high, it can cause more requests to accumulate in the local queue of the inference
servers, potentially increasing waiting time of users and leading to timeout errors at the load balancer due to
prolonged delays in responding to these requests. Requests exceeding the MAX_CONCURRENT_REQUESTS limit (or the local
queue length) will be rejected by the servers as a backpressure mechanism. Client applications interacting with the
inference servers should incorporate traffic control and retry logic to enhance resilience.
Container Gateway or Job Queue?
Container Gateway
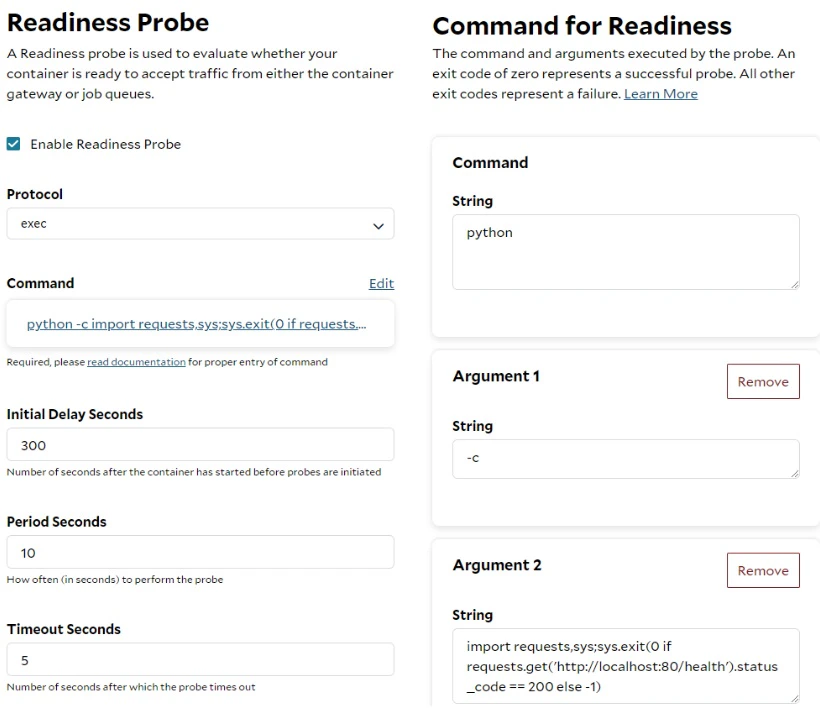
Deploying a container group with a container gateway (load balancer) is the simplest approach for providing real-time and on-demand services on SaladCloud. The inference server on each instance should listen on an IPv6 port, and the container gateway can map a public URL to this IPv6 port. Optionally, you can enable authentication to access the URL using an API token. To support LLM inference efficiently, the container gateway can be configured to use the Least Connections algorithm and forward concurrent requests to the inference servers in a container group. The server response timeout setting controls how long the container gateway will wait for a response from an instance after sending a request, with a maximum limit of 100 seconds. This timeout affects the maximum length of generated text (for non-streaming) and the number of requests that can queue locally on inference servers. For more information on load balancing options and how to adjust these settings to fit your needs, please refer to this guide. To use this solution effectively, system requirements and capabilities should be clearly defined and planned to properly configure the inference servers. Deploying the Readiness Probes is also essential to ensure that requests are only forwarded to containers when they are ready. Additionally, the client applications should implement retries and traffic control mechanisms to further enhance system resilience. Currently, all container instances, regardless of their locations, are centrally exposed by the load balancer in the U.S. While this setup is optimal for instances running in America, it may introduce additional latency for instances in other regions. However, this is generally acceptable given that LLM inference normally takes much longer (tens of seconds) than this. If applications are latency-sensitive and require local access, consider using open-source tools or services like ngrok, and implementing your own load balancer in the relevant regions.Job Queue
A container group integrated with a job queue offers a more resilient and cost-effective solution for batch processing systems where immediate responses are not required. You can submit millions of jobs to a job queue, which could be Salad JQ or AWS SQS. Instances with an I/O worker and the inference server, will then pull and process the jobs, subsequently uploading the generated texts to predefined locations, such as cloud storage or a webhook. The job queue features a large buffer for queuing requests and includes built-in retry logic. If an instance does not complete a job within a specified time, the job becomes available to other instances for processing. Each instance pulls new jobs only after finishing the existing ones, eliminating the need for mechanisms like backpressure, retries, and traffic control in both the inference servers and client applications. To implement this solution, you need to build a wrapper image that adds an I/O worker to the inference server. This worker will be responsible for pulling jobs, calling the inference server, uploading the generated texts and finally returning job results or status to the job queue.Build Your Own Queue
Several customers have successfully implemented a Redis-based, flexible and platform-independent queue for LLM applications on SaladCloud, demonstrating the following advantages:- Supports both asynchronous and synchronous calls, with results provided in streaming or non-streaming modes.
- Enables regional deployment to ensure local access and minimize latency.
- More resilient to burst traffic, node failures, and the variability in AI inference times, while allowing easy customization for specific applications.
Local Deployment To SaladCloud
Before deploying an image of these inference servers on SaladCloud, we recommend testing it in a local environment first. Troubleshooting and fine-tuning parameters in the cloud can be time-consuming and complex. For local deployment and testing, focus on the following objectives:- Ensure everything is functioning as expected.
- Monitor resource usage, including CPU, RAM, GPU, and VRAM, to inform resource allocation on SaladCloud.
- Test system behaviors with different parameters and finalize the configuration settings.
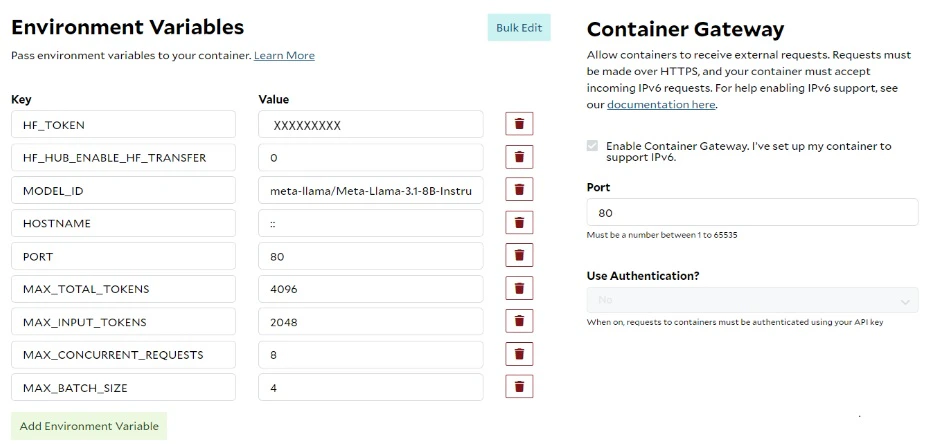
Scenario 1: Use environment variables to supply the working parameters to the TGI server.
Scenario 2: Override both the ENTRYPOINT and CMD in the image to start the TGI server.
Sometimes, we can configure the TGI server to start with additional parameters using specific values without needing to pass many environment variables. SaladCloud offers the option to override the ENTRYPOINT and CMD in the image, which easily accommodates this requirement.
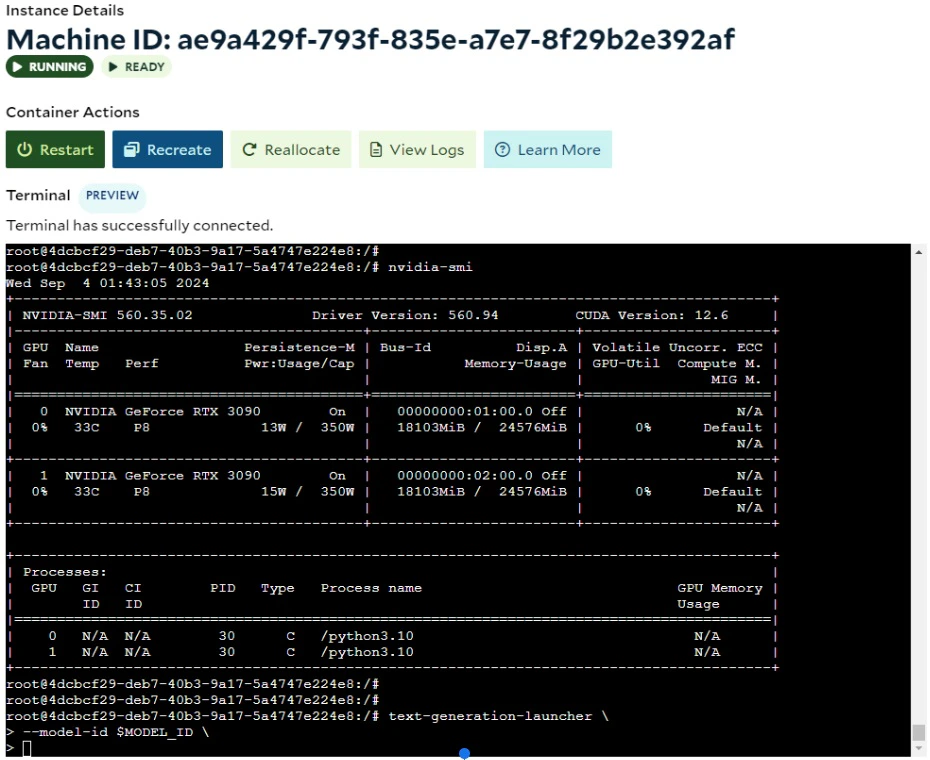
Scenario 3: Run the TGI server interactively.
SaladCloud Portal provides an interactive terminal for each instance in SCE deployments, allowing you to interact directly with each instance to troubleshoot issues or reconfigure your application after deployment. If you don’t have access to a local test environment with a GPU, you can use the interactive terminal on SaladCloud to test your image, check its resource usage, fine-tune and finalize server settings. Keep in mind that this is just a complement and cannot fully replace your local R&D environments for daily tasks, as SaladCloud nodes are interruptible and may experience cold starts and occasional downtime.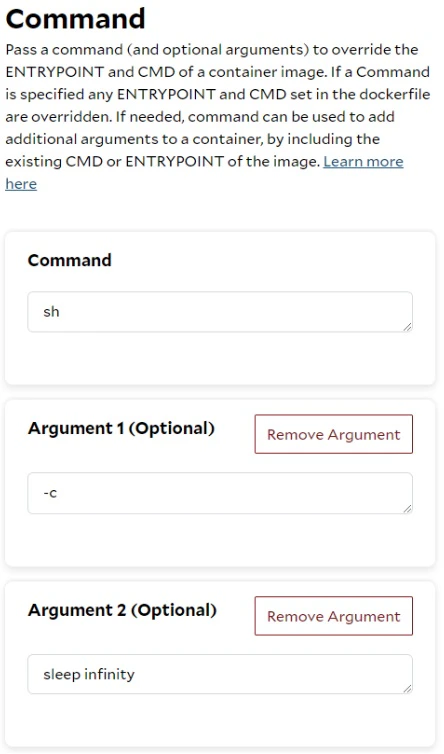
Recommendation for Production
The official images of these inference servers may not be sufficient for production. You can enhance your application by building a custom wrapper image with the following features:- Install the necessary softwares and tools, such as monitoring, troubleshooting and logging.
- Add an I/O worker to the inference server for pulling jobs, uploading generated texts and returning job results, especially if you’re building a batch processing system.
- Pre-load the model parameters into the image to reduce costs, as there’s no charge when nodes are downloading your images.
- Implement initial and real-time performance checks to ensure that nodes remain in an optimal state for application execution, as the performance of SaladCloud nodes may fluctuate over time due to their shared nature. If a node’s performance falls below a predefined threshold, the code should exit with a status of 1, triggering a reallocation. These functions can also be achieved by deploying Startup Probes and Liveness Probes.