Deploying TGI on Salad
Container
Hugging Face provides a pre-built docker available via the Github Container registry.Docker
CMD or can be set as
Environment Variables when creating your container group. Here
is a complete list of
all TGI options
Required - Container Gateway Setup
In addition to any options that you need to run the model, you will need to configure TGI to use IPv6 in order to be compatible with SaladCloud’s Container Gateway feature. This is done by simply settingHOSTNAME to ::

Recommended - Health Probes
Health Probes help ensure that your container only serves traffic it is ready and ensures that the container continues to run as expected. When the TGI container starts up, it begins to download the specific model before it can start serving requests. While the model is downloading, the API is unavailable. The simplest health probe is to check the/health endpoint. If the endpoint is
running, then the model is ready to serve traffic.
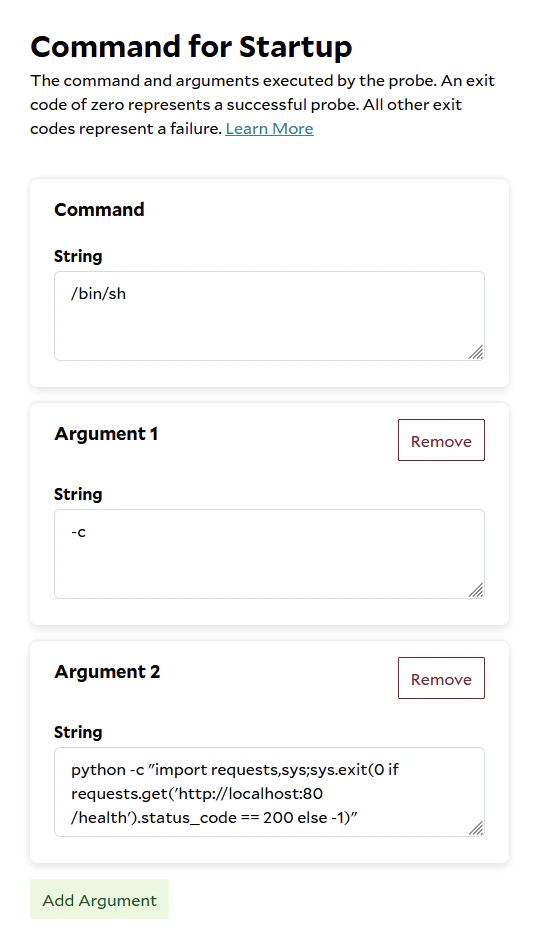
Exec Health Probe
Theexec health probe will run the given command inside the container, if the command returns an exit code of 0, the
container is considered in a healthy state. Any other exit codes indicate the container is not ready yet.
The TGI container does not include curl or wget so in order to check the :80/health API we decided to use python’s
requests to check the API.
bin
Required Environment Variables
-
SHARDED=trueEnables TGI’s sharded mode. If this is set and no additional options are provided, TGI will use all visible GPUs. RequiresCUDA_VISIBLE_DEVICESto be set to expose GPUs to TGI. -
NUM_SHARD=<int>Specifies how many shards to split the model across. Must match the number of GPUs you want TGI to use (and must be ≤ the number of visible devices). If this environment variable is set,SHARDEDis not required.CUDA_VISIBLE_DEVICESmust still be set to expose specified GPUs to TGI. -
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7Required to expose multiple GPUs to the TGI container. By default, TGI will only detect one GPU unless this variable is set. You can also use this to run multiple workloads on a single 8-GPU node by isolating which GPUs are used by each container. To specify which GPUs TGI should use, provide a list of integers as a value.
Example: Use All 8 GPUs


Example: Use Only 2 GPUs
